
Training Processes Specifics
General Information
Using personalized Appliance Models for each installation under examination provides an advantage over-generalized appliance models extracted from ground truth data due to the:
- The generalized models will require increased complexity to detect the appliance end-uses in every installation.
- The abundance of memory/space/time resources required to try and match many appliance models for each installation every day.
- There is a high possibility of unacceptably large numbers of false-positive end-use detections reported daily due to the low-quality generalized appliance models.
NET2GRID NILM approach a two-phase training process:
- Training Phase One: This process uses a small portion of historic Real-Time measurements data to create models for the Non-Time Based Appliances (AlwaysOn, Refrigeration, Lighting, Entertainment).
- Training Phase Two: This process uses as much historic Real-Time measurement data as available to create meaningful models for the appliances that are Time-Based or affected by seasonality and weather.
The reason for this gradual training and model extraction is to provide personalized and accurate disaggregation results for each appliance as soon as possible. Having relevant appliance models is bound to keep the customer well-informed and committed to the provided energy services. On the other hand, if the reports are not available or relevant after a short while, the customer will stop giving attention to the provided insights and recommendations.
The training processes mentioned above are presented in the following subsections.
Training Phase One (Statistical Appliances)
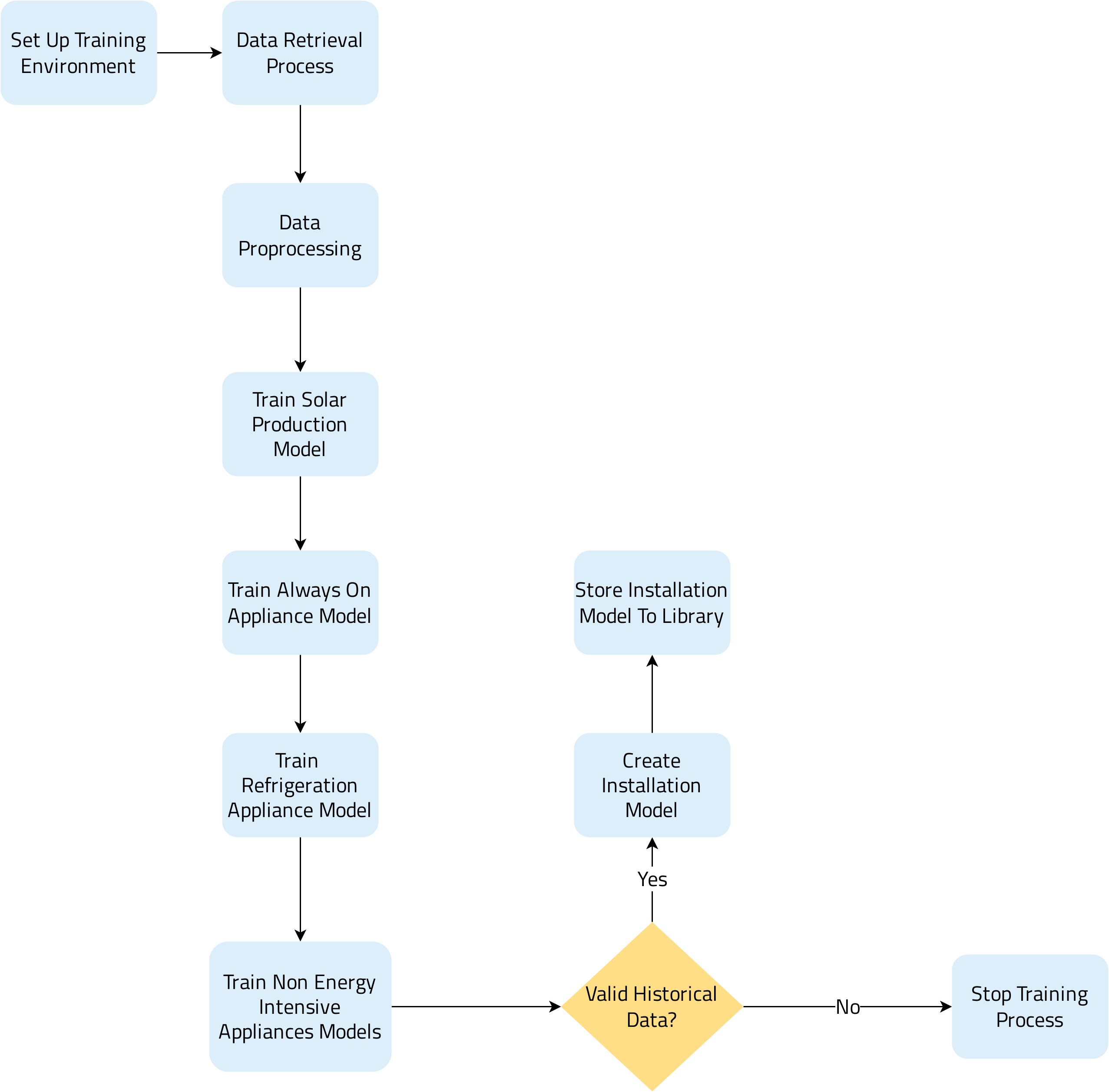
Training Non-Time Based Appliances is the first phase of the installation model training process based on Real Time energy consumption measurements. This process is responsible for creating an installation model containing specific statistical models that can be used to estimate the non-time-based appliance consumption in an installation, such as AlwaysOn, Refrigeration, Lighting, and Entertainment (see Supported Appliances subchapter).
Accurate AlwaysOn consumption estimation is crucial to i) extract helpful information about the energy efficiency of the installation and ii) estimate the refrigeration appliances’ consumption more accurately. To that end, several mathematical tools and algorithms are utilized to cope with diversity and in-house energy production (e.g., solar panels).
The refrigeration consumption must be identified and filtered from the measurements to avoid unnecessary complexity in the next steps. Three different implementations (analytical, projection-based, and statistics-based) are used for that purpose, depending on the circumstances.
Finally, as far as the non-energy-intensive appliances grouped under the categories of Lighting and Entertainment are concerned, a smart algorithm solution based on the AlwaysOn calculations across varying time windows within a day is utilized. Since these micro appliances consume less than 200 Watts, it is nearly impossible to detect standalone consumption events on measurements. Time zone and variation of daylight duration are considered in NET2GRID’s solution for Lighting as an attempt for the most accurate result.
AlwaysOn and Refrigeration consumption events occur during the day, while Lighting and Entertainment participate in the installation consumption during periods with tenants’ presence. Since their consumption is present for most of the day’s duration, we can provide accurate models within this time frame, in case the data quality is good enough (missing data per day do not exceed six (6) hours).
The Appliance Models extracted during this Training Process are stored in the Installation Model Database. They are utilized during the Daily Disaggregation process routine to map energy consumption end-uses to the identified appliances.
The following flowchart depicts the Statistical Appliances Training process visually.
Some important high-level specific details on the first phase of the Training Process are:
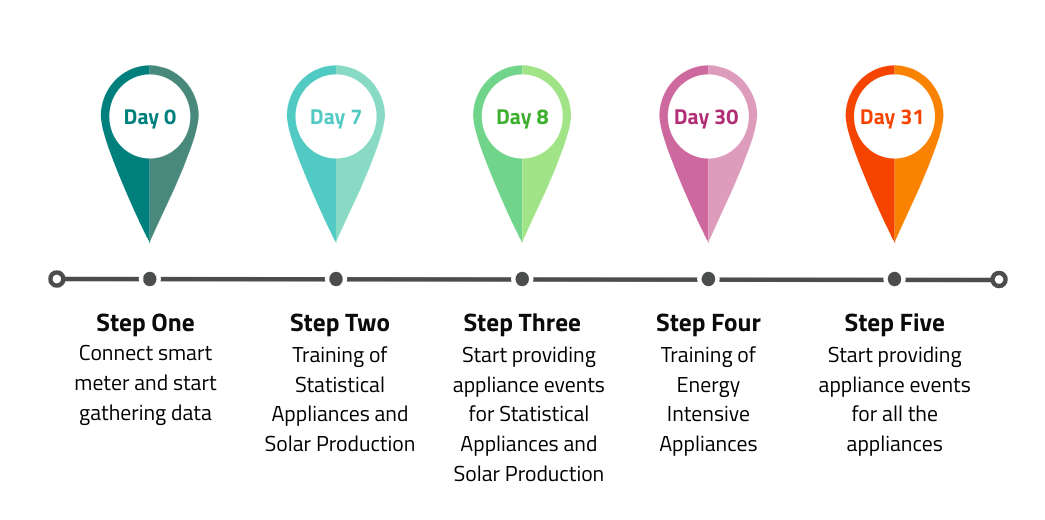
- The Training Statistical Appliances process requires at least seven (7) days of good-quality data.
- In case the first attempt for training Non-Time-Based Models is unsuccessful, the process is repeated each day until enough good-quality data days for the Statistical Models to be extracted.
- This process is executed again if there is a sizable statistical deviation of the estimated statistical appliance consumption during the daily disaggregation compared to the stored appliance models.
Training Phase Two (Energy-Intensive Appliances)
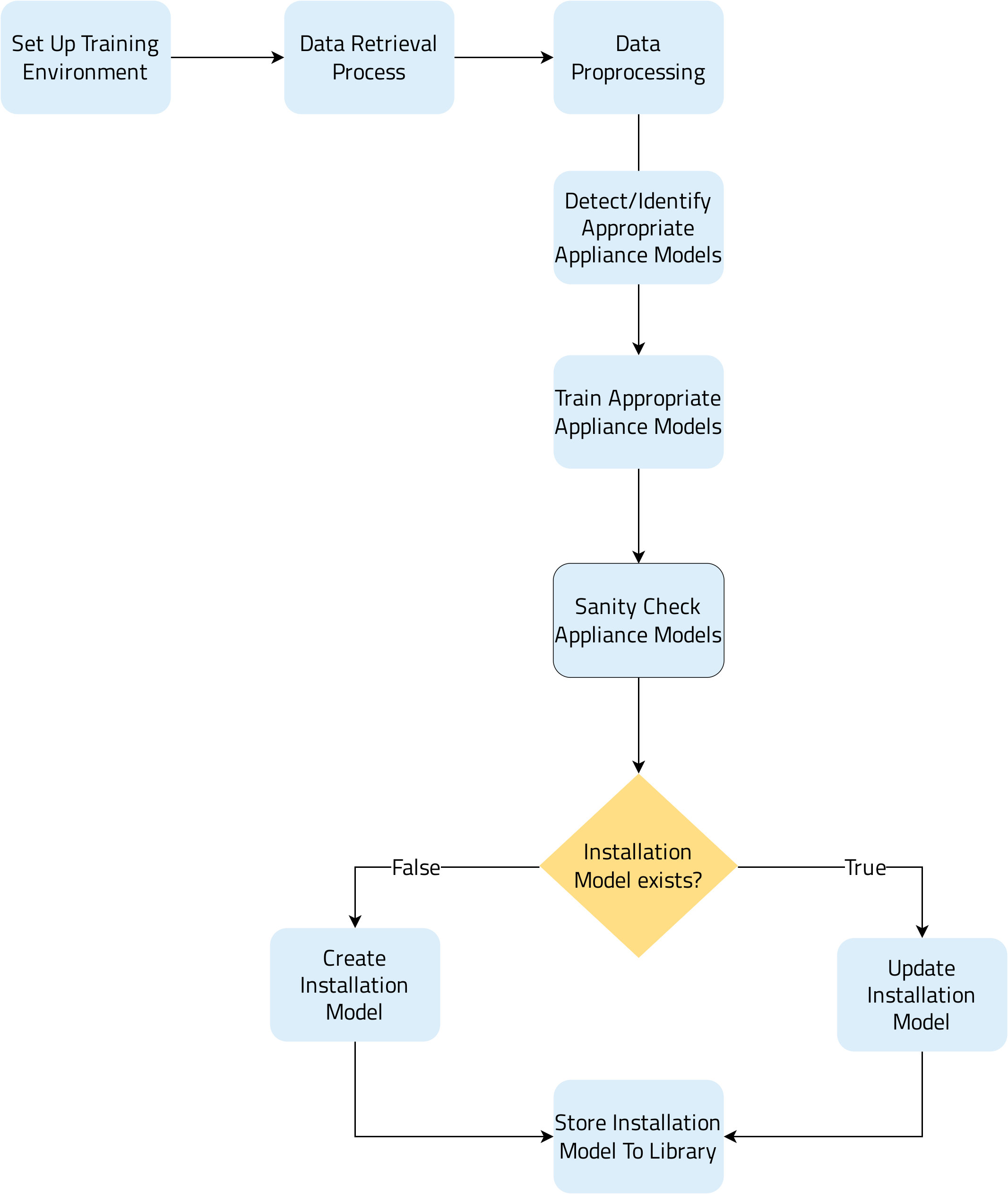
Training Energy Intensive Appliances process is the second phase of the installation model training based on active power measurements. This process is responsible for identifying and producing appliance models for all the energy-intensive appliances installed within a household, such as Dishwashers, Washing Machines, Tumble Dryers, etc.
Using personalized Appliance Models for each installation under examination provides an advantage over-generalized appliance models extracted from ground truth data due to the:
- The generalized models will require increased complexity to detect the appliance end-uses in every installation.
- The abundance of memory/space/time resources will be required to match many appliance models for each installation every day.
- There is a high possibility of an unacceptably large number of false positive end-use detections reported daily due to the wrong generalized appliance models.
The Energy Intensive Appliance Models extracted during this Training Process are then stored in an installation model in the Analytics Library. They are utilized during the Daily Disaggregation process routine to map appliance end-uses to the identified appliances.
The following flowchart depicts the training of energy-intensive appliances in a visual way.
Some important high-level specific details on the second phase of the Training Process are:
- The Training Energy Intensive Appliances process requires 30 days of good-quality data.
- This process is executed as much as three times, as long as there are missing Appliances Models, based on the provided Installation Profile. Thus, this training process can be executed in 30, 60, and 90 days.
- There is also a retraining service that works in an automated and manual manner. The automated process is triggered by changes in the profile provided by the user, while the user’s requests trigger the manual process.
NILM Status Based on Training
After discussing the most appropriate way to communicate the training progress information to the customer, it was agreed that a new attribute should be added to the NILM Status report.
To this end, the NILM Phase Status is utilized, which is a number that shows at which point in the Training Process the specific installation is currently situated. More specifically, the proposed phase statuses are set as below:
- NILM Status 0: No Training Process has run up to this point in time. (This would be the default when no NILM status is available at all in the backend)
- NILM Status 1: Training Phase One has run at least once, and statistical appliance models are available.
- NILM Status 2: The training process Phase Two has run at least once, and at least some energy-intensive appliance models are created.
- NILM Status 3: The automated training process has been completed for this installation.
The following diagram depicts the previous points more graphically:
